NVIDIA RAG Blueprint を AKS に乗せてみた——Helmコマンド一発で動くまでの理解と気づき

Microsoft AI Tour for Partners に参加した際に、NVIDIA提供のハンズオンセッション「RAG Pipeline with Nemotron on AKS」を体験した。MicrosoftパートナーとしてAzureとNVIDIA双方の技術スタックが組み合わさるセッションで、実際にコマンドを叩いてシステムを動かせる内容だった。
Azure上でNVIDIAのRAG Blueprintを動かすハンズオンに参加した。Helmコマンドを数回叩くだけでLLM推論・ベクターDB・ドキュメント取り込みパイプラインが一括起動し、PDFに質問できるUIまで立ち上がる体験は、想像以上に示唆が多かった。
手順を追いながら気づいたことを記録しておく。
やったこと
AKS(Azure Kubernetes Service)上にKubernetesクラスターを用意し、NVIDIA GPU OperatorとRAG BlueprintをHelmでデプロイした。最終的にはブラウザからPDFをアップロードして「このドキュメントの主なトピックは?」と質問できる状態まで到達した。
構成はシンプルに言うとこうだ。
Azure
└── AKS(マネージドKubernetes)
├── NVIDIA GPU Operator(GPUをKubernetesリソースとして管理)
└── NVIDIA RAG Blueprint(Helmで一括デプロイ)
├── NIM(LLM推論)
├── 埋め込みモデル
├── nv-ingest(ドキュメント取り込みパイプライン)
├── Milvus(ベクターDB)
├── Redis(セッション管理)
└── フロントエンドUI
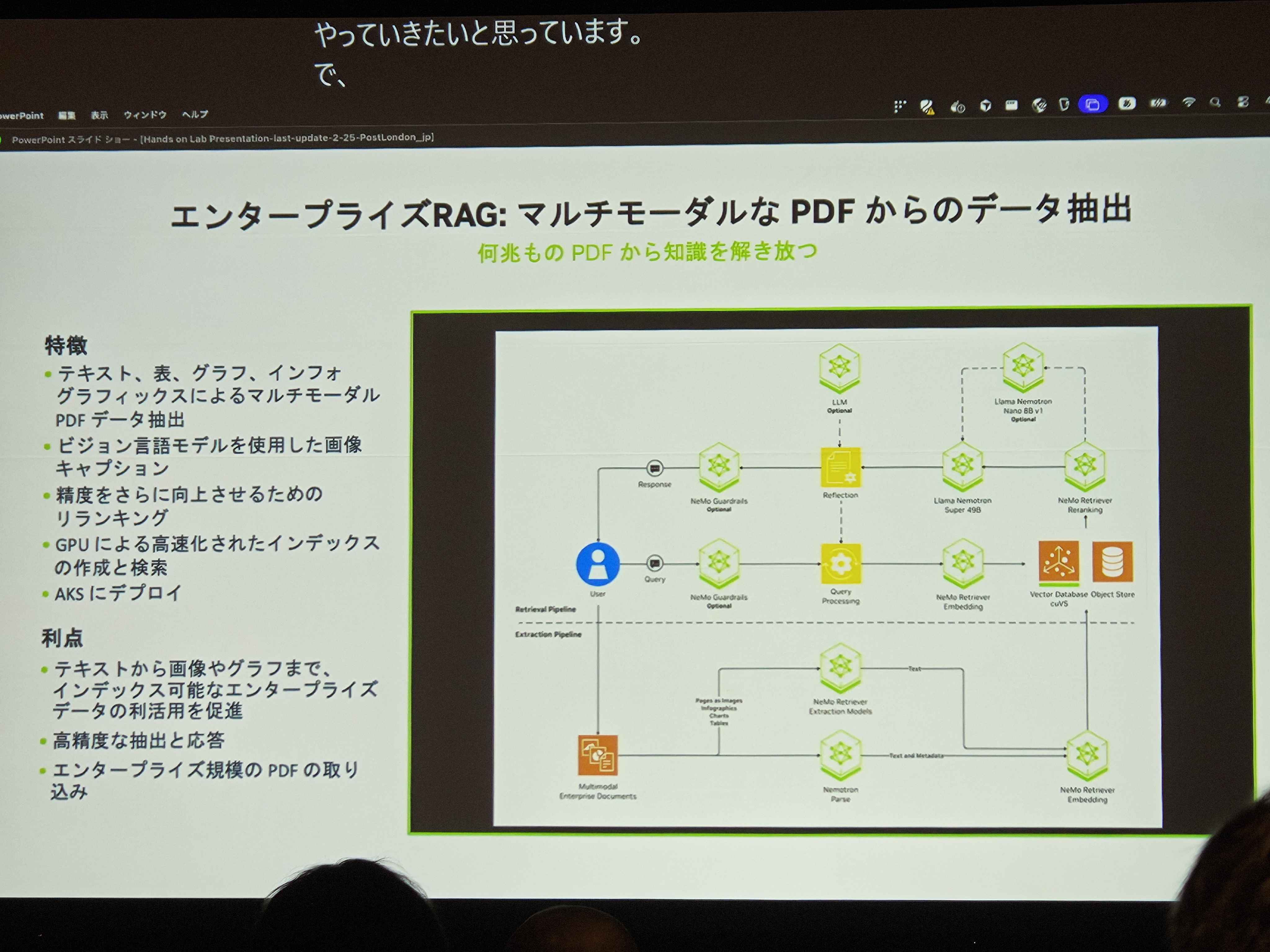
セッションで紹介されたアーキテクチャ図がこちらだ。「エンタープライズRAG:マルチモーダルなPDFからのデータ抽出」というテーマで、何兆ものPDFから知識を引き出すパイプラインの全体像が示されていた。
Task 1:環境設定——az aks get-credentials の意味
最初のタスクはAzure Cloud Shellを開いて環境変数を設定し、AKSクラスターへ接続することだ。
az extension add --name aks-preview
export NGC_API_KEY=<YOUR NVIDIA API KEY>
export RESOURCE_GROUP=ResourceGroup1lod60651116
export CLUSTER_NAME=rag-demo
export NAMESPACE=rag
az aks get-credentials --resource-group $RESOURCE_GROUP --name $CLUSTER_NAME
az aks get-credentials は手元の kubectl がAzure上のクラスターを向くよう ~/.kube/config を書き換えるコマンドだ。これ以降の kubectl コマンドがすべてそのクラスターに対して実行される。ローカルの操作感でクラウドのKubernetesを操作できる仕組みで、AKSの使い勝手のよさの一端を感じた。
Task 2:NVIDIA GPU Operator——GPUをKubernetesのリソースにする
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia --pass-credentials && helm repo update
helm install --create-namespace --namespace gpu-operator nvidia/gpu-operator --wait --generate-name
kubectl get pods -n gpu-operator
GPU Operatorは「KubernetesからGPUを nvidia.com/gpu という形で扱えるようにする」ためのオペレーターだ。これがないと、PodにGPUを割り当てる以下の指定が機能しない。
resources:
limits:
nvidia.com/gpu: 2
CPUやメモリと同じ書き方でGPUを指定できるのは、このオペレーターがドライバーのインストールやデバイスプラグインの登録をすべて自動化してくれているからだ。
ここで意識したこと:Podが全部 Running になるまで待つ必要があるが、Init:0/1 や PodInitializing と Running の違いが最初わかりにくかった。kubectl get pods -n gpu-operator -w でリアルタイムに状態を見ながら待つと、KubernetesのPodライフサイクルが体感として理解できた。
Task 3:RAG Blueprintのデプロイ——Helmコマンドの長さの意味
helm upgrade --install rag --create-namespace --namespace $NAMESPACE \
https://helm.ngc.nvidia.com/nvidia/blueprint/charts/nvidia-blueprint-rag-v2.3.0.tgz \
--set imagePullSecret.password=$NGC_API_KEY \
--set ngcApiSecret.password=$NGC_API_KEY \
--set nim-llm.resources.limits."nvidia\.com/gpu"=2 \
--set nv-ingest.nemoretriever-graphic-elements-v1.deployed=false \
--set nv-ingest.nemoretriever-table-structure-v1.deployed=false \
--set nv-ingest.paddleocr-nim.deployed=false \
--set nv-ingest.nemoretriever-ocr.deployed=false \
--set nvidia-nim-llama-32-nv-rerankqa-1b-v2.enabled=false \
--set ingestor-server.envVars.APP_NVINGEST_EXTRACTTEXT=True \
--set ingestor-server.envVars.APP_NVINGEST_EXTRACTINFOGRAPHICS=False \
--set ingestor-server.envVars.APP_NVINGEST_EXTRACTTABLES=False \
--set ingestor-server.envVars.APP_NVINGEST_EXTRACTCHARTS=False
オプションが多くて面食らうが、読んでいくとこのコマンドが「フル構成からGPUを使うコンポーネントを選択的にオフにしている」ことがわかる。
| オフにしたもの | 理由 |
|---|---|
nemoretriever-graphic-elements-v1 | グラフ・図の認識モデル、GPU必要 |
nemoretriever-table-structure-v1 | 表構造認識モデル、GPU必要 |
paddleocr-nim / nemoretriever-ocr | OCR、GPU必要 |
rerankqa | リランキングモデル、GPU必要 |
ENABLEGPUINDEX / ENABLEGPUSEARCH | ベクター検索のGPUアクセラレーション |
つまり今回動かしたのはRAG Blueprintのテキストのみ最小構成だ。フル構成が持つ能力の輪郭を、オフにした項目の多さから逆算して理解できる構造になっていた。
気づき:なぜグラフ認識の後にOCRが必要なのか
ハンズオン中に気になったことがある。graphic-elements(グラフ認識)と table-structure(表認識)があるのに、なぜ別途OCRが必要なのか、という点だ。
整理するとこういうことだ。
グラフ画像の検出(graphic-elements)
↓ 「グラフがここにある」を認識する
グラフの中の文字を読む(OCR)
↓ 「X軸: 2020〜2024」「Y軸: 売上高」を取得する
テキストとしてベクターDBに格納
表の構造を認識(table-structure)
↓ 「行・列・セルの関係」を理解する
セルの中の文字を読む(OCR)
↓ 「| Q1 | 100万円 | 前年比+5% |」を取得する
テキストとしてベクターDBに格納
構造認識モデルは「どこに何があるか」を理解するが、文字は読まない。 OCRが「その中に何と書いてあるか」を担当する。2種類のモデルがそれぞれの専門を担う分業構造になっている。
最終的にRAGの検索対象になるのはテキストだから、グラフや表の中の情報も文字列に変換して初めて「検索できるデータ」になる。この2段階の設計は理にかなっている。
Task 4:UIへのアクセス——LoadBalancerとExternal IPの待ち方
kubectl -n $NAMESPACE expose deployment rag-frontend \
--name=rag-frontend-lb --type=LoadBalancer --port=80 --target-port=3000
kubectl -n $NAMESPACE get svc rag-frontend-lb --watch
--watch フラグをつけると、External IPが割り当てられるのをリアルタイムで観察できる。<pending> が実際のIPアドレスに変わる瞬間を見たとき、「AzureのロードバランサーがKubernetesのServiceと繋がった」という実感があった。
アクセスするとPDFをアップロードしてコレクションを作り、そのまま質問できるUIが動いていた。
やってみてわかったこと
Helmチャート1つの意味が大きい
LLM・ベクターDB・取り込みパイプライン・UIを個別にセットアップしようとすると、構成管理・バージョン整合性・ネットワーク設定など多くの手間がかかる。それがHelmチャート1つとパラメータ指定で揃う。プロトタイプの検証フェーズでの価値は高い。
Helmのもう一つの強みは環境ごとの使い分けが --set の書き換えだけで済むことだ。今回のハンズオンではGPUリソースを節約するためにいくつかのコンポーネントをオフにしたが、それも全て --set で制御していた。
# 個人・検証環境:GPUコスト最小、テキストのみ
--set nim-llm.resources.limits."nvidia\.com/gpu"=1
--set nv-ingest.nemoretriever-graphic-elements-v1.deployed=false
--set ingestor-server.envVars.APP_VECTORSTORE_ENABLEGPUINDEX=False
# 商用・本番環境:フル構成、高精度
--set nim-llm.resources.limits."nvidia\.com/gpu"=4
--set nv-ingest.nemoretriever-graphic-elements-v1.deployed=true
--set ingestor-server.envVars.APP_VECTORSTORE_ENABLEGPUINDEX=True
同じチャートを使いながら、スイッチを切り替えるだけで「コストを抑えたPoC環境」と「フル性能の本番環境」を使い分けられる。これを自前で管理しようとすると、環境ごとに設定ファイルが乱立しがちだが、Helmならチャートは1つのまま values.yaml や --set で差分だけ管理できる。
オフにしたコンポーネントが気になる
今回テキストのみで動かしたが、フル構成ではマルチモーダルな取り込みが動く。表やグラフを含む技術文書・財務報告書など、従来のキーワード検索ではうまく扱えなかったドキュメントも対象にできる可能性がある。
特に日本語のPDFで試してみたい。PaddleOCRは日本語をどこまで読めるのか、nv-ingestの文章分割は日本語の文節境界をどう扱うのか——テキストのみの構成でも日本語ドキュメントの精度は気になる点だ。
Pod起動の待機は「失敗か正常か」の判断が難しい
10分程度のPod起動待機時間がある。Init:0/1 や CrashLoopBackOff が出てくると、失敗しているのか初期化中なのかわかりにくい。KubernetesのPodステータスを事前に把握しておくと、この待機時間がより落ち着いて過ごせる。
API Keyの扱いは実務では要注意
ハンズオンでは export NGC_API_KEY=... と環境変数に直接エクスポートする手順だったが、実務でこれをそのまま使うのは危険だ。Kubernetes Secretや、AzureであればKey Vaultとの連携が必要になる。ハンズオンの簡便さと本番運用の安全性の違いを意識しておきたい。
次に試したいこと
- マルチモーダル構成の有効化:表・グラフ込みのPDFで精度がどう変わるか
- 日本語PDFでの動作確認:文字化けや文章分割の挙動
- リランキング有効時との比較:回答品質の変化を定量的に見る
- Guardrailsの設定:不適切な質問への対応をどう設定するか
RAGの「型」を最短で体験するには申し分ないブループリントだった。次のステップは自分たちのデータで動かすことだ。
ハンズオン環境:Azure Kubernetes Service (AKS) + NVIDIA GPU Operator + NVIDIA RAG Blueprint v2.3.0